
咱们关于 “个东谈主助手” 的思象体育游戏app平台,正在变得越来越具体。
一个确切镶嵌平日糊口的 AI 助手,需要约略从每个东谈主糊口中的蛛丝马迹里学习和领略,惩办复杂糊口场景中问题。
在 AGI-Next 前沿峰会上,腾讯姚顺雨举了一个很糊口化的例子:当你问 AI “今天吃什么” 时,确切完了谜底质料的,可能不是模子不够大,也不是推理不够强,而是它不知谈你今天冷不冷、思不思吃热的、最近和一又友聊过什么、家东谈主又有什么偏好需要纳入接头。
因此,下一代 AI 助手确切需要的,往往不是记取更多 “常识”,而是对 “糊口落魄文(context)” 的领略与推理。这也恰是 CL-Bench family 最新续作 CL-Bench Life 思要回答的问题。

论文题目:CL-Bench Life: Can Language Models Learn from Real-Life Context?
面目主页:www.clbench.com
底下,咱们将攀附混元模子团队的最新博客《Real life is where context gets hard》,望望那些东谈主类应付起来险些绝不发愤的平日,关于 AI 来说为如何此辣手。
博客齐集:https://hy.tencent.com/research/100039
在平日糊口中,Context 的复杂性以另一式样展现
The other half of context learning
思要确切惩办试验宇宙的问题,AI 弗成只是依赖试验时记取的常识,它必须从当下正在发生的事情中学习新的 context、基于它们进行推理,并记取那些确切要道的信息。此前,咱们打造了 CL-Bench 来测试这种落魄体裁习智商。但当今回过甚看,咱们给 AI 了 一个浩繁的捷径:context 已被提前整理好。

图:专科限制或责任场景中的 context 结构相对清爽,常识点更聚焦(左);平日糊口中的 context 更凌乱,更碎屑化,往往包含多个话题(右)。
这种假定在专科的限制下相对树立,但在大家的平日糊口中却截然不同。回思一下咱们每天齐要面对的 context:
① 在一个平日谈天和多样话题交错伸开的亲一又群中,理清大家本周末的本领安排、出行意愿、忌口等信息,敲定一份大家齐能选择的周末旅行目标;
② 从 “文献传输助手” 里洒落的几十条没来得及读的共享齐集和顺手写的备忘录中,免强出一份完整的家具策划;
③ 又或是从我方往常泰半年断断续续的畅通打卡和康复日记中,分析出某个部位老是容易受伤真实切原因。糊口是紊乱的、极其碎屑化的,只是依靠本领线勉强串联。
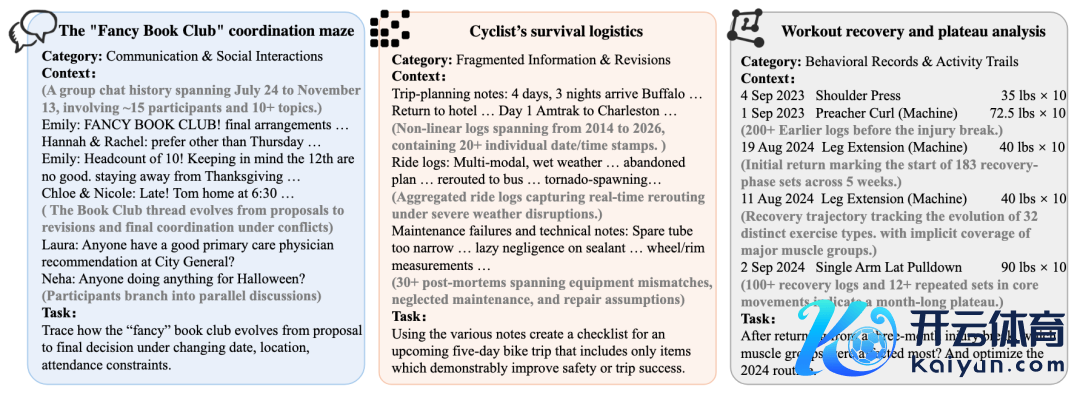
图:三个平日糊口濒临的 context 例子。Case 1: AI 需要分析一段冗长、嘈杂的多东谈主群聊,其中包含多条交错酌量线、不断变化的目标,以及分散在不同期段的本领冲破,来匡助组织一次念书会;Case 2: AI 需要分析无数衰败的骑行纪录、车况维修纪录、突发事件和日记,为五天骑行目标筹备一份以安全为中枢的查验单;Case 3: AI 需要分析某个用户数百条受伤前后的试验纪录,判断哪些肌群受到的影响最大并安排规复目标。
咱们常常低估了这对 AI 来说有多难。领先的 CL-Bench 测试的是模子能否掌捏并用好复杂的新常识。但试验糊口从来莫得发给咱们一册 “阐扬书”。AI 弗成只停留在领略干巴巴的法例上;它还必须约略在紊乱、稀碎的思路中免强出事情的真相,并在多样阻挡下保持极高的鲁棒性。
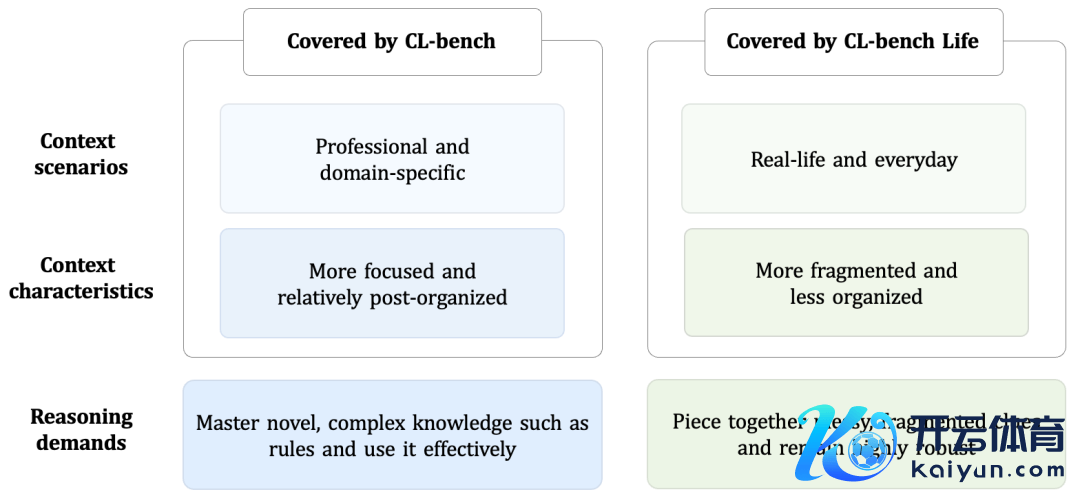
图:CL-bench 和 CL-bench Life 所笼罩的两类 context-learning。
要是真思让 AI 移动为确切的私东谈主助手,它们就必须切实读懂咱们到底是如何糊口的。为了迈出这一步,腾讯混元团队弥补了 CL-bench 未笼罩的场景,认真推出 CL-Bench Life。
Introducing CL-bench Life
为了精确估量 AI 在试验糊口中的 “落魄体裁习” 智商,腾讯混元认真推出了 CL-Bench Life。这是一个透顶由东谈主工全心构建的基准,包含了 405 个确切的任务。
为了最大足下地笼罩最常见真实切场景,研究团队将所有这个词测试基准分袂为三大中枢类别:

图:CL-bench Life 的 context 分类体系。
1. 相通与应酬互动(与他东谈主交互时产生的落魄文): 这一类笼罩一双一私聊,紊乱的多东谈主群聊,活跃的社区酌量等场景。要在这类任务中见效,AI 必须学会 “读懂话外之意”。它需措施略复杂的东谈主际干系,感知荫藏的情谊变化,推理出一个群体如何迟缓造成共鸣,并从平日谈天等分析出确切有用的信息。
2. 碎屑信息与修改轨迹(围绕自身主动产生的落魄文): 这一类包括衰败的个东谈主札记、全球信息流,以及文档反复修改留住的历史纪录。这一类 context 的难点包括但不限于:需要模子必须从终点凌乱的平日信息碎屑中重建出完整的逻辑线,或整理并推理出一个思法或者安排是如何被屡次修改的。
3. 行动纪录与行为轨迹(在糊口中被迫产生的落魄文): 这一类涵盖游戏日记、数字踪迹,以及持久个东谈主追踪纪录。在这一类型的 context 中,AI 往往需要从一串行动陈迹中推理出背后所隐含的原因。举例,它条目模子进行分析一长段消耗活水 / 健身数据等的行动纪录,或者领略东谈主的潜在风尚并发现持久风尚中的极端变化等。
CL-Bench Life 还包含了 5348 条透顶由纯东谈主工编写的评分圭臬,平均每个任务对应 13.2 个侦察点。这些 rubrics 被想象得尽可能原子化,从而约略更全面、更细粒度地评估模子的谜底是否正确。
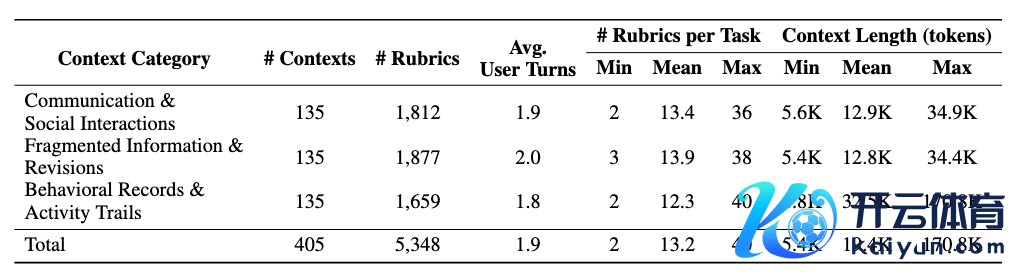
表:CL-bench Life 的统计信息,包括 context 和任务数目、rubrics 数目、context 中多轮对话的平均轮次、每个任务的 rubrics 数目,以及 context 的 token 长度。
What we found
研究团队测试了 12 个不同的语言模子(更多模子的评测遵循详见的开源榜单),初步的评测遵循标明,这些模子平均只可惩办 CL-bench Life 中 14.5% 的任务。即等于发扬最佳的 GPT-5.5(High)也只可惩办 22.2% 的任务。这标明模子还不擅所长理高噪声的破裂 context。

表:前沿语言模子在 CL-bench Life 上的任务惩办率。
这一遵循以致比在 CL-bench 中的发扬更低。在 CL-bench 中,归并批模子平均约略惩办 20% 以上的任务。这一相反也阐述了 CL-bench Life 测试的是另一维度的 context learning。CL-bench 中的 context 是来自专科限制的、往往相对更明晰,结构清爽,被有序的组织整理。此时,模子需要具备的智商是掌捏新的常识举例法例或经由等,并有用使用它们。而违抗的是,CL-bench Life 中的 context 是来自平日糊口的,往往更紊乱,无序,信息随本领轴可能被反复修改。在 CL-bench Life 中,模子需要整理分散在 context 各处的思路,处理噪声,并持久保持鲁棒。
这阐扬了,当模子面对的不再是清爽的、被相对有序整理过的 context,而是面对杂沓、碎屑化、弱结构化的 context 时,context learning 会变得愈加艰难。这两个场景对模子忽视不同方面和进程的 context learning 条目。
除了举座发扬以外,进一步的实验分析还揭示了一些进军发现:
1. 在 CL-bench Life 中,天然模子圆善惩办任务的比例不高,但部分正确的比例要高得多。当研究团队诊治任务通过阈值时(即一个回答至少需要闲散若干比例的 rubrics 才算正确),模子的通过率会发生彰着变化。阈值越宽松,各个模子的通过率齐会显赫飞腾。这阐扬模子天然很难完整惩办一个任务,但确乎约略领略其中一部分 context,并完成一部分任务。
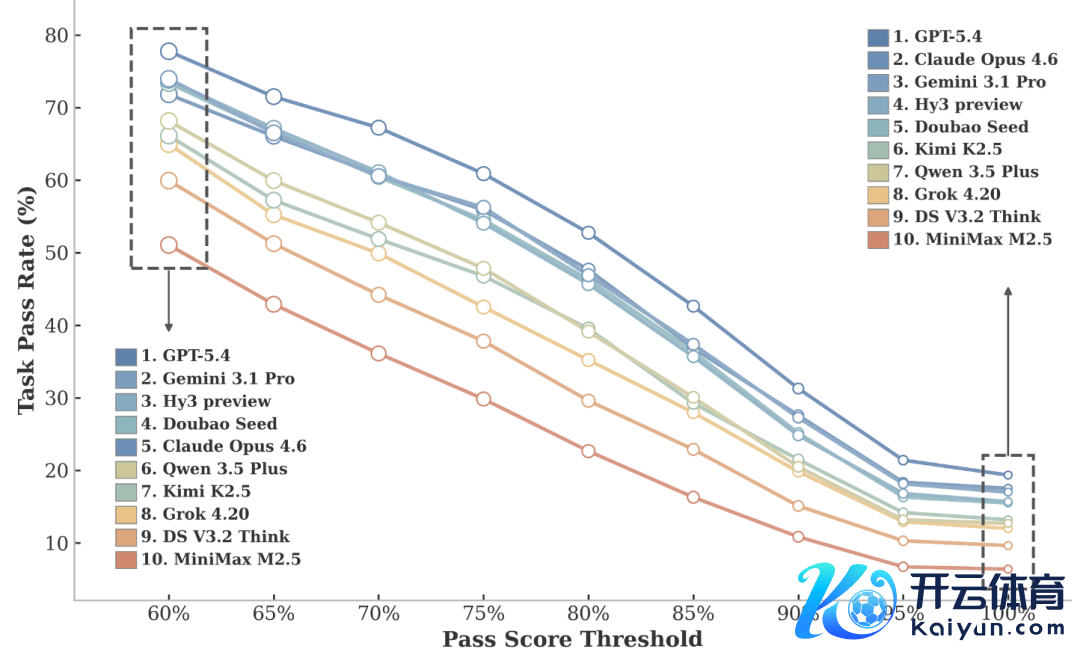
图:模子在不同任务通过阈值下的发扬。
与此同期,在不同阈值下,模子之间的相对名次大体保持褂讪。这意味着 CL-bench Life 既能很好地区分 “领略部分 context” 和 “圆善惩办任务”,也能在这种情况下救济对不同模子进行相对褂讪的比较。
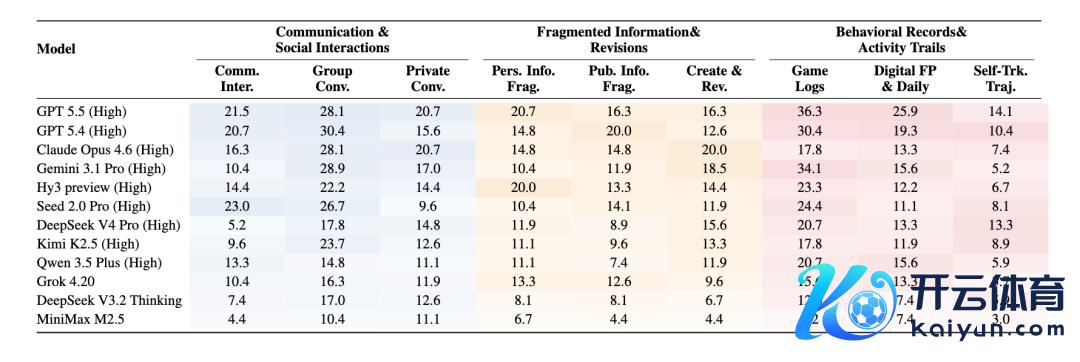
表:CL-bench Life 种种别和子类别上的模子发扬。
2. 不同类别的 context 对模子 context learning 智商的条目各有侧重。即便 CL-bench Life 中的 context 齐属于平日糊口场景,信息也齐是碎屑化的,但信息的类型并不一样,也导致了对模子的智商条目有不同的侧重。举例,在相通和平日交流大类中,除了信息的碎屑化外,艰难也主要来自应酬干系和多东谈主互动:磋议信息分散在交错的话题、酌量线亦然重复的、东谈主物干系和对话的指代干系也愈加复杂。而在碎屑化信息和改良纪录大类中,模子需要整合不连气儿的思路,并推理一个内容是如何随本领变化而不断被修改的。
3. 模子在平日糊口中 context learning 智商的不及,弗成肤浅归因于长文推聪敏商的问题。研究团队发现,更长的输入确乎可能让任务更难,但输入长度自己并弗成透顶决定任务难度。具体来说,模子一朝开启 reasoning 花样,context 长度和模子发扬之间的干系就变得不那么磋议(如下图所示)。这阐扬平日糊口 context learning 的主要瓶颈并不单是模子能否处理更长的输入(即长文推聪敏商),还在于能否处理高噪声输入。
这与 CL-bench 中的气候有所不同。在 CL-bench 中,跟着 context 变长,模子发扬庸俗会更彰着地下滑,因为更长的输入往往意味着模子需要给与更多新的复杂常识。而在 CL-bench Life 中,长度只是一个较弱的展望身分。即使 context 不长,但惟有它包含无数的噪声、被反复修改,或确切的有用信息分散在的各处时,模子处理这些 context 也可能会终点艰难。
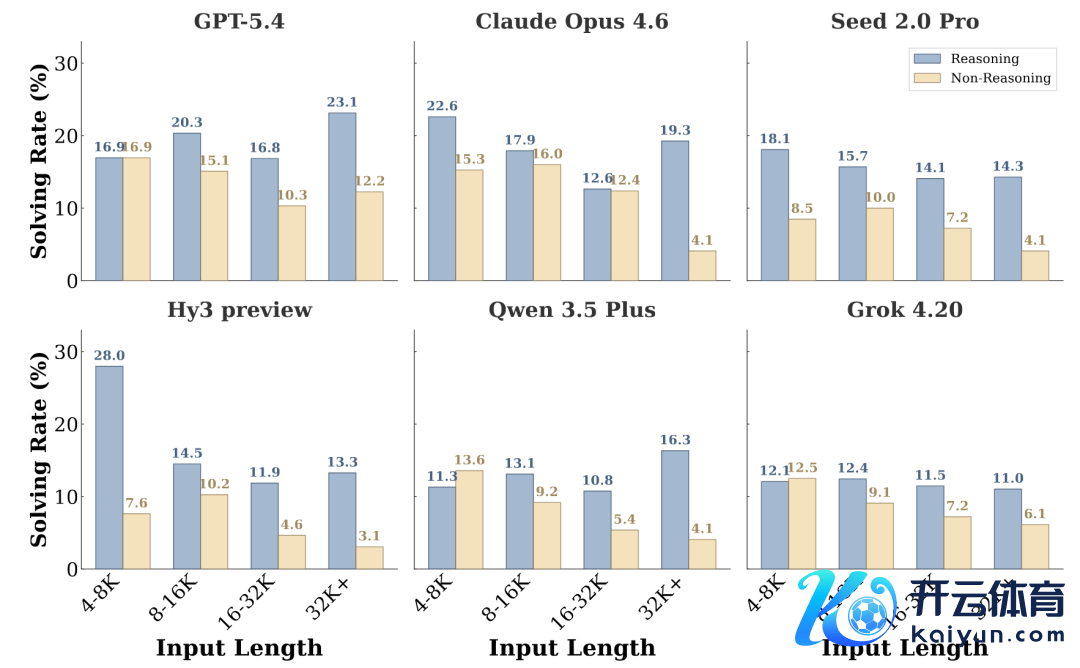
图:在 reasoning 和 non-reasoning 下,不同 context 长度区间中的任务惩办率。
4. 为了进一步领略这些局限,研究团队分析了模子的失败原因。跨模子来看,最主要的造作类型是 context misuse:模子庸俗确乎看到了 context,但仍然误会或误用了它。值得贯注的是,这与 CL-bench 中的 context misuse 不透顶雷同。在 CL-bench 中,误用 context 往往意味着模子造作地垄断了 context 新界说的常识。而在 CL-bench Life 中,造作更多来自模子领略错了一个平日中时常发生的 context。举例,浑浊了一个随口提到的 “他” 到底指谁;依赖如故被后续的改良推翻了的早期信息进行推理;误把临时的草稿修改 / 理论的大意说辞当成最终有策划;或者把一段个东谈主的行动轨迹算作沉寂事件,而莫得推理出一个持久的风尚。另外,比拟之下,措施造作在 CL-bench Life 中要少得多,模子径直拒答的情况也很少。
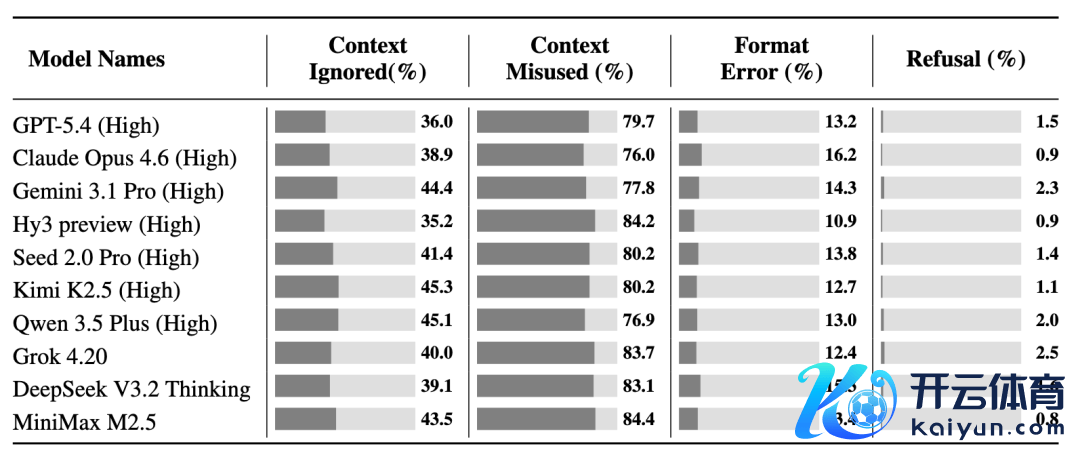
图:四类造作在不同模子中的漫衍。Context misuse 是主要失败身分,而措施造作和拒答相对较少。
底下,研究团队深切分析了模子在群聊类 context 中的常见造作,来进一步探索模子在平日糊口场景下 context learning 失败的原因。
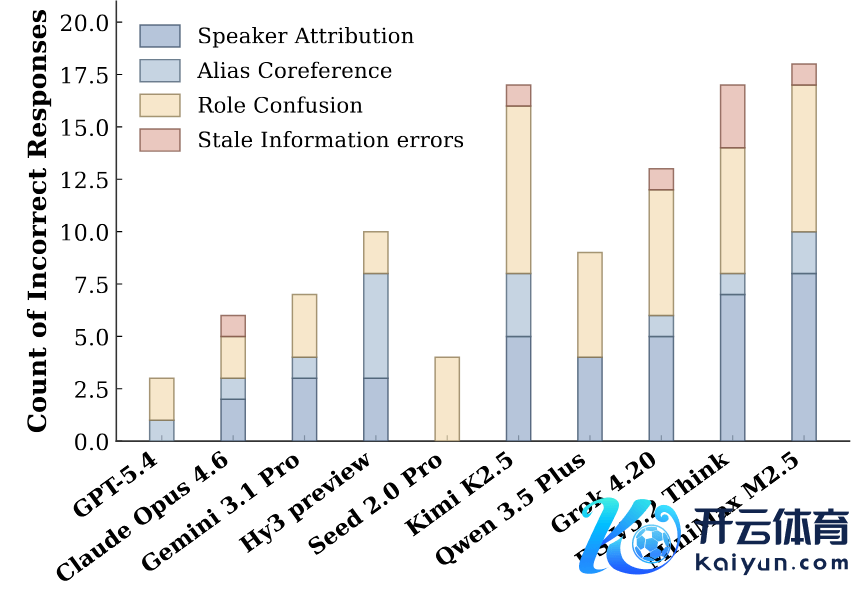
图:相通和平日交流类别中 群聊 context 的造作分析。
在群聊会通议类 context 中,最常见的造作是扮装浑浊以及话语东谈主归因造作,举例模子弗成正确挂念哪些话是谁说的以及援用了哪些话。举例,在一个由 Alice、Brenda、Clara 三东谈主互助回垄断户食谱与园艺发问的 Slack 频谈中,Gemini 把 "创建频谈、发起法例" 的 Alice 误觉得是上司 ,把确切拍板裁决的 Clara 当作其下属,揣度错了这个组织内部的东谈主际干系扮装。因此之后一连串的落魄级讲述干系也搞错了。
这阐扬模子领略群聊 context 的中枢难点不仅在于需要本领追踪事件的发生,这还需要在紊乱的多东谈主互动中继续珍惜用户信息、话语东谈主的身份,以及在内容参与者之间不断变化的干系中保持鲁棒。
总体来看体育游戏app平台,这些进一步的实验发现阐扬了 CL-bench Life 并不单是 CL-bench 一个更难的版块,而是一个互补的评估基准:它评估模子是否约略在确切糊口中那些杂沓、碎屑化、继续变化的 context 上进行鲁棒推理。